The Building Blocks of Modern AI
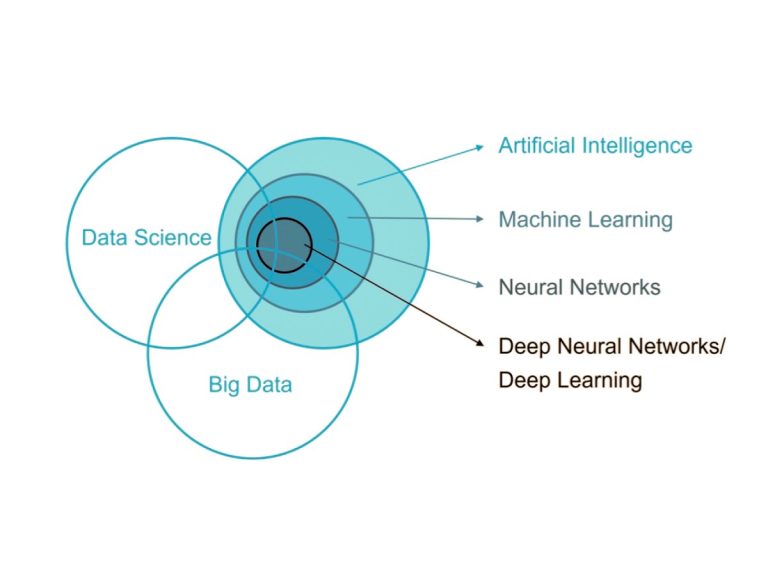
Deep Learning has become one of the most important advancements in Artificial Intelligence (AI), driving significant breakthroughs in various fields, from natural language processing to computer vision. Central to Deep Learning are Deep Neural Networks (DNNs), which mimic the way the human brain processes information. In this post, we’ll explore what Deep Learning and Deep Neural Networks are, how they work, and why they are so influential in the world of AI.
What is Deep Learning?
Deep Learning is a subset of Machine Learning (ML) that focuses on using complex structures called neural networks to model and solve problems that involve vast amounts of data. Unlike traditional ML algorithms that require feature engineering and domain expertise, Deep Learning can automatically discover the patterns and features in the data through multiple layers of processing.
Key Characteristics of Deep Learning:
- High Data Requirements: Deep Learning models typically require large datasets to perform well, as they learn directly from the data.
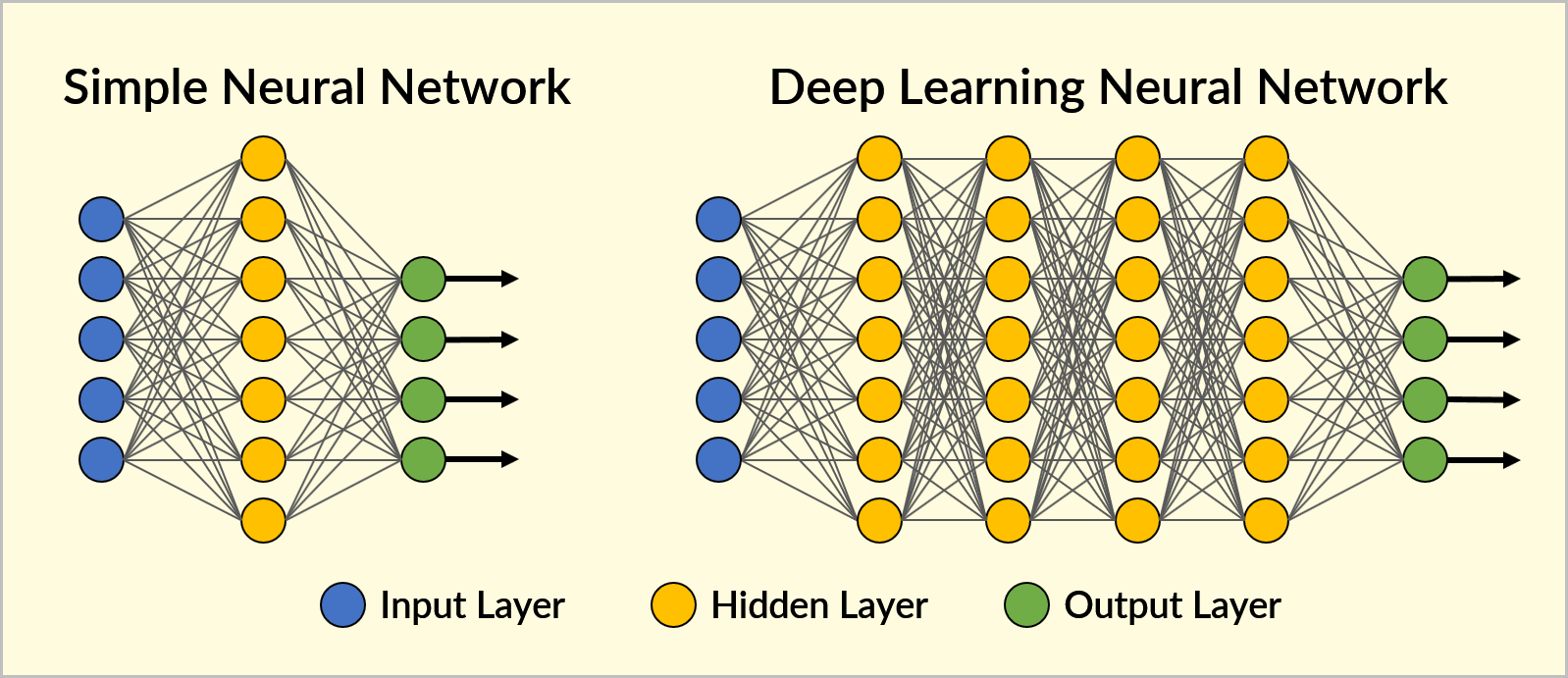
- Multiple Layers: The “deep” in Deep Learning refers to the presence of multiple layers of neurons in the network, each layer learning increasingly abstract features from the data.
- End-to-End Learning: Deep Learning models are often trained in an end-to-end manner, meaning they can learn to perform a task directly from raw data input to the final output.
What are Deep Neural Networks (DNNs)?
Deep Neural Networks (DNNs) are the architectures used in Deep Learning. They are inspired by the structure and function of the human brain, where billions of interconnected neurons process information. Similarly, a DNN consists of multiple layers of artificial neurons (also known as nodes or units) that work together to analyse and interpret data.
Structure of a Deep Neural Network:
-
Input Layer: This is where the raw data enters the network. Each node in this layer represents a feature or input value, such as pixel values in an image or words in a text.
-
Hidden Layers: These are the layers between the input and output layers. The network may have multiple hidden layers, each consisting of many neurons. The neurons in hidden layers are responsible for extracting and transforming features from the input data. The more hidden layers a network has, the deeper it is, and the more complex patterns it can learn.
-
Output Layer: This layer produces the final prediction or output, such as a classification label or a continuous value. The number of neurons in the output layer depends on the task—for example, one neuron for binary classification or multiple neurons for multi-class classification.
-
Weights and Biases: Each connection between neurons has an associated weight, which determines the importance of the input value. Biases are additional parameters that help the network fit the data better.
-
Activation Functions: After the weighted sum of inputs is calculated, it passes through an activation function, which introduces non-linearity into the network, allowing it to learn and model complex patterns.
How Deep Neural Networks Work
The learning process in a DNN involves adjusting the weights and biases to minimise the error between the predicted output and the actual output. This process is done through an algorithm called backpropagation, which calculates the gradient of the loss function (a measure of error) and updates the weights accordingly using an optimisation technique like gradient descent.
Here’s a step-by-step breakdown:
-
Forward Pass: The input data is fed through the network, layer by layer, until it reaches the output layer, where the prediction is made.
-
Loss Calculation: The network’s prediction is compared to the actual target, and a loss (or error) is calculated. Common loss functions include Mean Squared Error (MSE) for regression tasks and Cross-Entropy Loss for classification tasks.
-
Backward Pass: The loss is propagated back through the network, and the weights are adjusted to reduce the error. This process is repeated many times, with the network gradually improving its performance.
-
Training and Convergence: The network is trained over many iterations, known as epochs, until the loss converges to a minimum, indicating that the model has learned the best possible representation of the data.
Applications of Deep Learning and Deep Neural Networks
Deep Learning and DNNs have revolutionised many fields, enabling the development of technologies that were previously thought to be out of reach. Some of the most prominent applications include:
-
Computer Vision: DNNs are used in image recognition, object detection, and facial recognition systems, enabling machines to interpret and understand visual data.
-
Natural Language Processing (NLP): Deep Learning models power applications like speech recognition, machine translation, and sentiment analysis, allowing machines to understand and generate human language.
-
Autonomous Vehicles: Deep Learning is a key component in the development of self-driving cars, helping them interpret sensor data and make real-time decisions.
-
Healthcare: DNNs are used in medical imaging to detect diseases, predict patient outcomes, and assist in drug discovery.
-
Generative Models: DNNs are behind generative models that can create new content, such as generating realistic images, music, or even deepfake videos.
Why Deep Learning Matters
Deep Learning has become a cornerstone of modern AI because of its ability to process and learn from vast amounts of data. Unlike traditional models, which often struggle with complex data, DNNs can automatically discover intricate patterns and relationships. This capability makes them indispensable in industries where precision, accuracy, and scalability are critical.
Leveraging AWS for Deep Learning
AWS offers a comprehensive suite of tools and services to support Deep Learning initiatives, making it easier for businesses to harness the power of DNNs:
-
Amazon SageMaker: Simplifies the process of building, training, and deploying DNNs, allowing you to scale your Deep Learning models efficiently.
-
AWS Deep Learning AMIs: Pre-configured with popular Deep Learning frameworks like TensorFlow, PyTorch, and Apache MXNet, these Amazon Machine Images (AMIs) enable you to start training models quickly on AWS’s powerful infrastructure.
-
AWS Inferentia: A high-performance machine learning inference chip designed to accelerate the performance of DNNs, reducing latency and cost for large-scale deployments.
-
Amazon Elastic Inference: Allows you to attach just the right amount of GPU-powered inference acceleration to any Amazon EC2 or SageMaker instance, optimising the cost-performance balance for DNN applications.
Conclusion
Deep Learning and Deep Neural Networks represent the cutting edge of AI, offering unparalleled capabilities to solve complex problems and unlock new opportunities across various industries. By leveraging AWS cloud services, businesses can harness the power of these technologies to drive innovation, improve efficiency, and gain a competitive edge in the market.
Whether you’re just starting with Deep Learning or looking to scale your existing models, our team at Paisums Technology is here to help you navigate this exciting landscape. Contact us today to learn more about how we can support your Deep Learning journey with AWS.